Kennis en expertise zijn de kernwaarden van CIMSOLUTIONS. Gericht op de kwaliteit van haar detacheringsdiensten, investeert CIMSOLUTIONS continu in de ontwikkeling van eigen medewerkers in de vorm van de thematische groeipaden, Special Interest Groups en Competence Centers. De laatste twee focussen op twee aspecten: het opbouwen van interne kennis en expertise en tegelijkertijd het ontwikkelen van de levensvatbare en demonstreerbare producten voor de externe klanten – beide zijn noodzakelijke ingrediënten voor asset-based consulting [1]. Op het gebied van data en kunstmatige intelligentie (AI) richt het ’Competence Center AI, Machine Learning en Robotics’ zich op de innovatieve ontwikkelingen van data gedreven applicaties en het gebruik van kunstmatige intelligentie; dit omvat een aantal interne projecten.
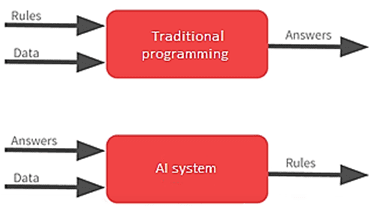
Traditioneel programmeren vs. zelflerend systeem
Het ontwikkelen van AI-systemen is net iets anders dan het ontwikkelen van traditionele software. In traditionele programmering worden expliciete regels vastgelegd in de code. Deze vaste regels samen met de input van nieuwe gegevens zorgen ervoor dat er altijd een eenvoudige output door het systeem wordt geproduceerd. In tegenstelling hierop is een andere aanpak nodig om AI zelf te laten leren. In plaats van de vastgestelde regels (die we vaak zelf niet eens kennen) geven we een aantal bekende antwoorden zodat de machine zelf op basis van deze antwoorden en daaraan gerelateerde input de regels kan formuleren. Als AI de regels heeft vastgesteld, dan kan het systeem voor nieuwe input zelf een antwoord bepalen.
Figuur 1 – Functioneel verschil tussen traditioneel programmeren en het AI systeem
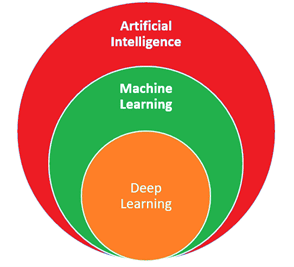
AI is een breed begrip en kan in twee onderdelen worden verdeeld (Figuur 2):
Machine learning richt zich op het zelfleren op basis van enkele statistische eigenschappen van de input gegevens en verbonden antwoorden;
Deep learning (onderdeel van zowel AI als machine learning) is meer gericht op het zelfleren op basis van grote (vaak ongestructureerde) gegevens door het trainen van complexe meerlaagse neurale netwerken.
Dat laatste wordt tegenwoordig met groeiende hoeveelheden data en computer rekenkracht steeds populairder, omdat het veel complexere problemen zoals beeld-, spraak- of tekstherkenning kan oplossen. Deze trend zien we ook terug in de markt – Gartner heeft 7,777 referenties voor het term “deep learning”, veel meer dan voor “machine learning” (5,639) en “AI” (4,457) [3].
Figuur 2 – de scope van AI / Machine Learning / Deep Learning [2]
Hoe leert moderne software zien, luisteren en praten?
Net zoals traditionele software werkt het neurale netwerk met de digitale numerieke input (cijfers). Om deze reden kan dit systeem niet rechtstreeks van tekst, audio of video input leren en moet het dus eerst deze informatie naar cijfers omzetten. De manieren waarop deze input wordt omgezet, wisselt per type probleem:
Voor beeld-/videoherkenning leert het netwerk op basis van de pixel codering van een afbeelding: lengte x breedte x RGB (kleuren) schaal. Hetzelfde geldt voor video’s, met het verschil dat het daar kijkt naar alle losse frames alsof het losse afbeeldingen zijn;
Voor tekstherkenning zet het netwerk eerst alle woorden om in cijfers, welke worden bepaald op basis van de overeenkomsten in betekenis tussen de woorden. Hoe meer de betekenis van de woorden overeenkomt, hoe dichter hun cijfers bij elkaar zullen liggen;
Voor spraakherkenning moet eerst het analoge audiogeluid naar een digitaal signaal geconverteerd worden, bijvoorbeeld door een analoog-digitaalomzetter. Het probleem wordt verder gereduceerd tot tekstherkenning door het digitale signaal op te breken in fonemen (kleinste klankeenheden) en er de meest waarschijnlijke woorden aan te koppelen.
Op de schouders van reuzen staan
Het trainen van deep learning modellen op basis van enorme datasets kan zeer rekenintensief zijn en vereist meerdere leeriteraties die vele dagen kunnen duren, zelfs op krachtige Graphics Processing Units (GPU’s). Daarom is het vaak een goed idee om eerst te zoeken naar reeds bestaande modellen die al zijn getraind op vergelijkbare data en van deze vervolgens de modelparameters aan te passen zodat slechts enkele specifieke iteraties kunnen worden gebruikt om het model op de specifieke gegevens door te trainen.
Figuur 3 – concept van transfer learning [4]
Van prototype naar productie
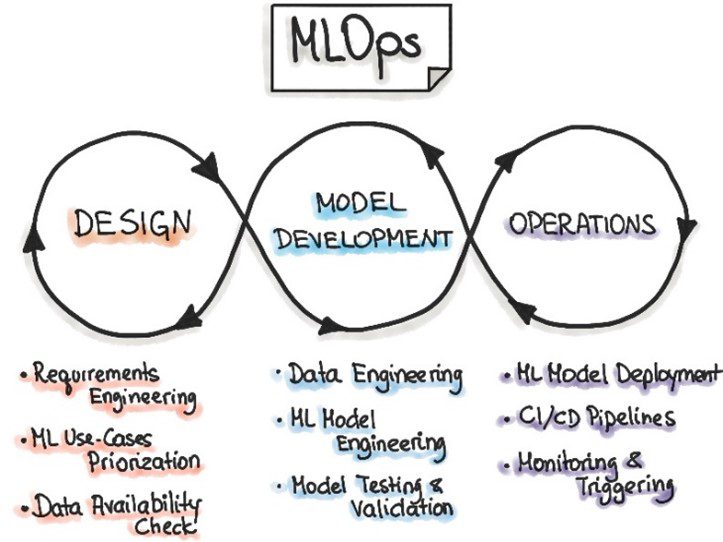
Het belangrijkste doel van het trainen van AI-systemen is om deze systemen uiteindelijk in productie te nemen zodat ze voorspellingen kunnen doen op basis van nieuwe data. Meerdere aanvullende componenten zoals databeheer, model serving en monitoring zijn vereist voor het robuust werken van het zelfvoorspelende systeem. In het kader hiervan is er recent een discipline ontstaan genaamd Machine Learning Operations (MLOps, ofwel DevOps voor Machine Learning [5]) die zich specifiek richt op het robuust, reproduceerbaar en beheersbaar maken van de end-to-end levenscyclus van voorspelmodelontwikkeling in elk deel ervan.
Figuur 4 – Iteratief-incrementeel proces in MLOps [5]
Het volgen van deze principes garandeert stabiele voorspellingen en tijdige signalering wanneer het model opnieuw moet worden getraind (bijvoorbeeld als input gegevens of bedrijfsprocessen veranderen).
Het huidige AI-nieuws wordt voornamelijk gedomineerd door generatieve AI en Large Language Models (LLMs). Hoewel deze modellen indrukwekkende prestaties leveren, hebben ze ook hun beperkingen.
Quantum computers kunnen complexe berekeningen en analyses vele malen sneller en efficiënter uitvoeren dan de traditionele computers waar we dagelijks mee werken.
Het belangrijkste doel van het trainen van AI-systemen is om deze systemen uiteindelijk in productie te nemen zodat ze voorspellingen kunnen doen op basis van nieuwe data.
Zo vriendelijk als “hello world” ook klinkt, zo naïef kan het zijn als men op basis van deze “hello world” voorbeelden beslist of een techniek of service ook gebruikt kan worden om de eigen “Real world” problemen op te lossen.
Om tot een Flow in de ontwikkeling van nieuwe producten en diensten te komen, is het zeer effectief gebleken gebruik te maken van een framework om flexibel en adaptief klantwensen in te richten.
AI en Machine Learning zijn volop in ontwikkeling, ook in het testvak. De AI testtools worden geavanceerder en frameworks om zelf iets te ontwikkelen worden toegankelijker. Dat leidt tot de vraag wat de rol van de tester nog is zodra de AI toepassingen volledig zijn ontwikkeld binnen het testvak.